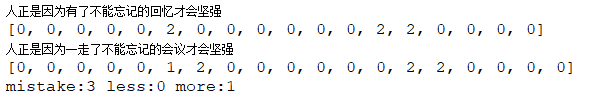对上一篇文章看打模式串匹配算法问题解决,正文前给个优化前算法的问题错误实例
-322b56ad2c794218b45f1b80d0e71ce8.png) 按照我设置的算法这个计算并没有错误,但实际上的确是存在逻辑错误的,错误依据
原文(a串):人正是因为有了不能忘记的回忆才会坚强
跟打(b串):人正是因为一走了不能忘记的会议才会坚强
理论识别错误:人正是因为“多”“错”了不能忘记的“错错”才会坚强
实际识别错误:人正是因为“多”“错”了不能忘记的“漏漏漏”会“多多多”坚强
发现,两个字“回忆”,“会议”应该对应错误,但在原算法中,是错位的。第一个位的“会议”的会匹配到了“才会”的会,导致机器无法识别的错误发生。
按照我设置的算法这个计算并没有错误,但实际上的确是存在逻辑错误的,错误依据
原文(a串):人正是因为有了不能忘记的回忆才会坚强
跟打(b串):人正是因为一走了不能忘记的会议才会坚强
理论识别错误:人正是因为“多”“错”了不能忘记的“错错”才会坚强
实际识别错误:人正是因为“多”“错”了不能忘记的“漏漏漏”会“多多多”坚强
发现,两个字“回忆”,“会议”应该对应错误,但在原算法中,是错位的。第一个位的“会议”的会匹配到了“才会”的会,导致机器无法识别的错误发生。
后来使用了动态规划中的edit distance(编辑距离)算法变式解决了这一问题(来自凌风的建议[英打群群主])
什么是edit distance
怎么利用edit distance(下文建立在看懂链接中的算法基础上)
在上面链接中,已经将edit distance算法解释的非常清楚,不再详细描述。 在原edit distance算法中,是利用动态规划来计算任意字符串a转换成任意字符串b时最少操作次数为多少。 操作有三种,替换,删除,插入 举例: ac->acb就需要插入b。 acb->ac就需要删除b。 acb->acc就需要替换c为b。 三个操作替换,删除,插入就对应着跟打器中设定的,错误,漏字,多字。 而原edit distance只记录最少操作次数,并不记录具体操作类型。 因此需要改造变式,在原变式算法中
int edit_distance(char *a, char *b)
{
int lena = strlen(a);
int lenb = strlen(b);
int d[lena+1][lenb+1];
int i, j;
for (i = 0; i <= lena; i++) {
d[i][0] = i;
}
for (j = 0; j <= lenb; j++) {
d[0][j] = j;
}
for (i = 1; i <= lena; i++) {
for (j = 1; j <= lenb; j++) {
// 算法中 a, b 字符串下标从 1 开始,c 语言从 0 开始,所以 -1
if (a[i-1] == b[j-1]) {
d[i][j] = d[i-1][j-1];
} else {
d[i][j] = min_of_three(d[i-1][j]+1, d[i][j-1]+1, d[i-1][j-1]+1);
}
}
}
return d[lena][lenb];
}
对返回的这个数组d进行分析,利用简单的两个字符串找到规律。 a:fxya b:fxa 获得矩阵如下图,矩阵的最后一个数字即为最少操作数。
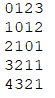

每填入一个数,如果下标对应的字符不同,就要进行min_of_three寻找周围数字最小值再+1,矩阵最短路径应为上图所示。 但机器只能将所有可能路径以矩阵列举出来,无法知道上一跳最短路径对应矩阵哪个位置。所以要将矩阵元素更改为能记录上一跳位置的类型。 即从最尾开始,提取出上一跳x,y再跳上去,再提取x,y以此类推,就根据已算出的矩阵获取路径。
既然有了最短路径了,只剩下怎么记录,错误,漏字,多字了。

可以分析得:
1、如果最短路径上一跳数值没有改变,即没有发生任何错误
2、如果最短路径上一跳数值被+1:
上一跳位置在d[i-1][j-1],即位置在左上方,两字符该位置为相对错字。 上一跳位置在d[i][j-1],即位置在上方,标记a串该位置多字,即相对b串该位置漏字。 上一跳位置在d[i-1][j],即位置在左方,标记b串该位置多字。
到这个时候,我们已经在逻辑上构造完毕,怎么实现呢,我贴出部分关键代码并给予解释
1、放置上一跳X,Y,操作数的内部类,实际就是为了存储矩阵x,y和值
class DataType {
int distance;
int prevX;
int prevY;
public DataType(int distance, int prevX, int prevY) {
this.distance = distance;
this.prevX = prevX;
this.prevY = prevY;
}
public int getDistance() {
return distance;
}
public int getPrevX() {
return prevX;
}
public int getPrevY() {
return prevY;
}
public void setDistance(int distance) {
this.distance = distance;
}
public void setPrevXY(int prevX, int prevY) {
this.prevX = prevX;
this.prevY = prevY;
}
}
2、创建两个数组,用作标记两字符串中,错误标记为2,各自多字的部分标记为1(a串多字相对b串漏字) 在while中用新建临时变量存放curX,curY的上一跳位置,再在标记完赋给curX,curY。直到curX或curY其中一个为零,即已到达了循环边界标记结束,退出循环
int curX = lenOrigin;
int curY = lenTyped;
int[] resOrigin = new int[lenOrigin];
int[] resTyped = new int[lenTyped];
while(curX != 0 || curY != 0) {
int prevX = data[curX][curY].getPrevX();
int prevY = data[curX][curY].getPrevY();
if (data[prevX][prevY].getDistance() == data[curX][curY].getDistance() - 1) {
if (prevX < curX && prevY < curY) { //Wrong word
resOrigin[curX - 1] = 2;
resTyped[curY - 1] = 2;
} else if (prevX < curX) { //less word
resOrigin[curX - 1] = 1;
} else { //more word
resTyped[curY - 1] = 1;
}
}
curX = prevX;
curY = prevY;
}
3、遍历数组resOrigin,数出a串中标记1的位置有多少个,即为漏字字数,遍历数组resTyped中,数出b串中标记1的位置有多少个,即为多字字数,数出b串中标记2的位置有多少个,即为错误字数(a,b串的标2位置相同,数一个数组即可)
给出几个调试结果
fxy和faby对比
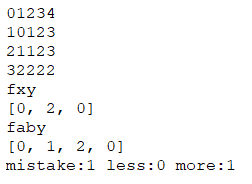
fxy和fy对比

fxy和fxya对比
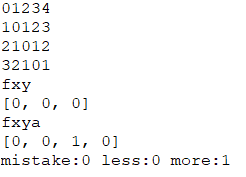
原算法出错位置